DNS
Before you can open a connection with any application, you first need to know where to find that application - aka its IP address. The following description of DNS is lifted from Nick’s blog post: DNSSEC: An Introduction.
Introduction
The Domain Name System (DNS) is one of the oldest and most fundamental components of the modern Internet. As the mechanism that maps domain names to Internet Protocol (IP) addresses, it provides a human-readable layer to navigate the millions of machines and devices on the Internet.
The concept of DNS is simple: it’s a global database of information about domain names. It’s the Internet’s phone book.
If a client wants to connect to an address such as www.example.com and needs to know which IP address corresponds to this address, they can ask DNS. Typically, all DNS messages are sent over UDP.
There are several types of Resource Records (RR) that DNS can answer questions about. One of the most important RRs is called an “A record”, which stores the IPv4 address associated with the domain. To find out the value of any record for a given domain, you can ask a DNS resolver. For example, it you wanted the IP address for www.example.com, the question you could ask is:
“What is the A record for the domain www.example.com?”
The raw DNS request is a UDP packet as shown in Listing 1. This request contains an ID (0x27e1), some flags to indicate that it is a request, and the question itself.
The response for our raw DNS request is shown in Listing 2. This response comes with the matching ID (0x27e1), a copy of the original request echoed back, some flags (1/0/0), and an answer to the question: 93.184.216.119. It also contains a validity period, called time to live (TTL), to indicate how long the record is valid.
Raw DNS request:
0x0000: 5ad4 0100 0001 0000 0000 0000 0765 7861 ‘............exa
0x0010: 6d70 6c65 0363 6f6d 0000 0100 01 mple.com.....
Wireshark’s interpretation:
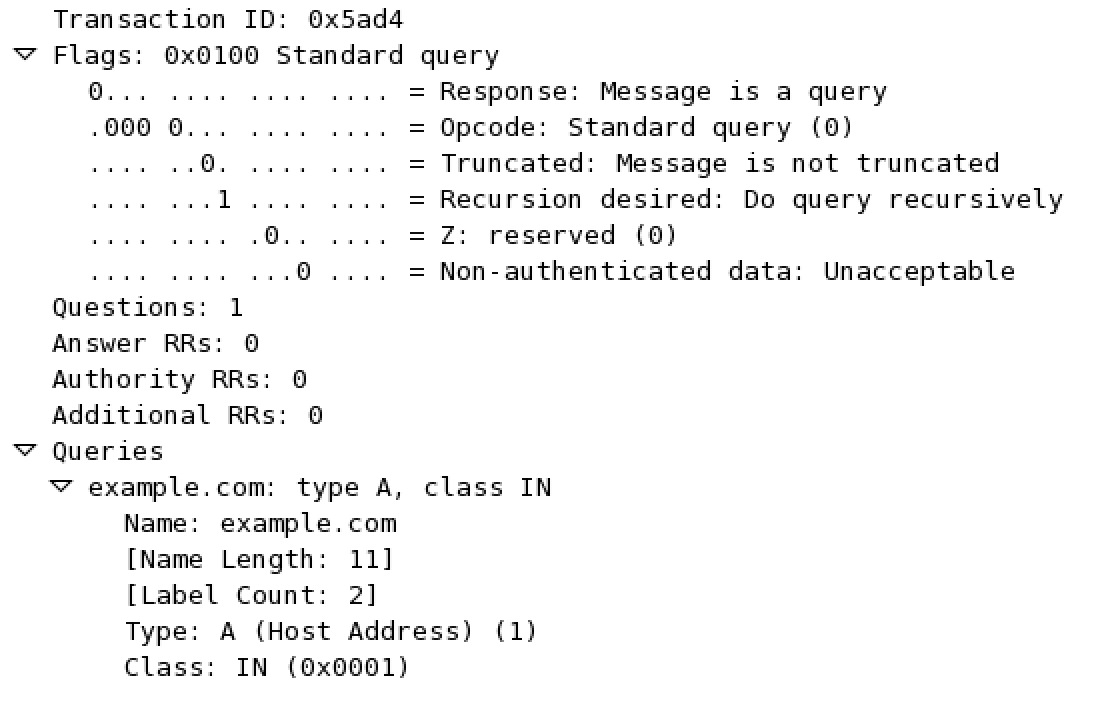
Raw DNS Response:
0x0000: 51d4 8180 0001 0001 0000 0000 0765 7861 ‘............exa
0x0010: 6d70 6c65 0363 6f6d 0000 0100 01c0 0c00 mple.com........
0x0020: 0100 0100 0031 f500 045d b8d8 77 .....1...]..w
Wireshark’s interpretation:
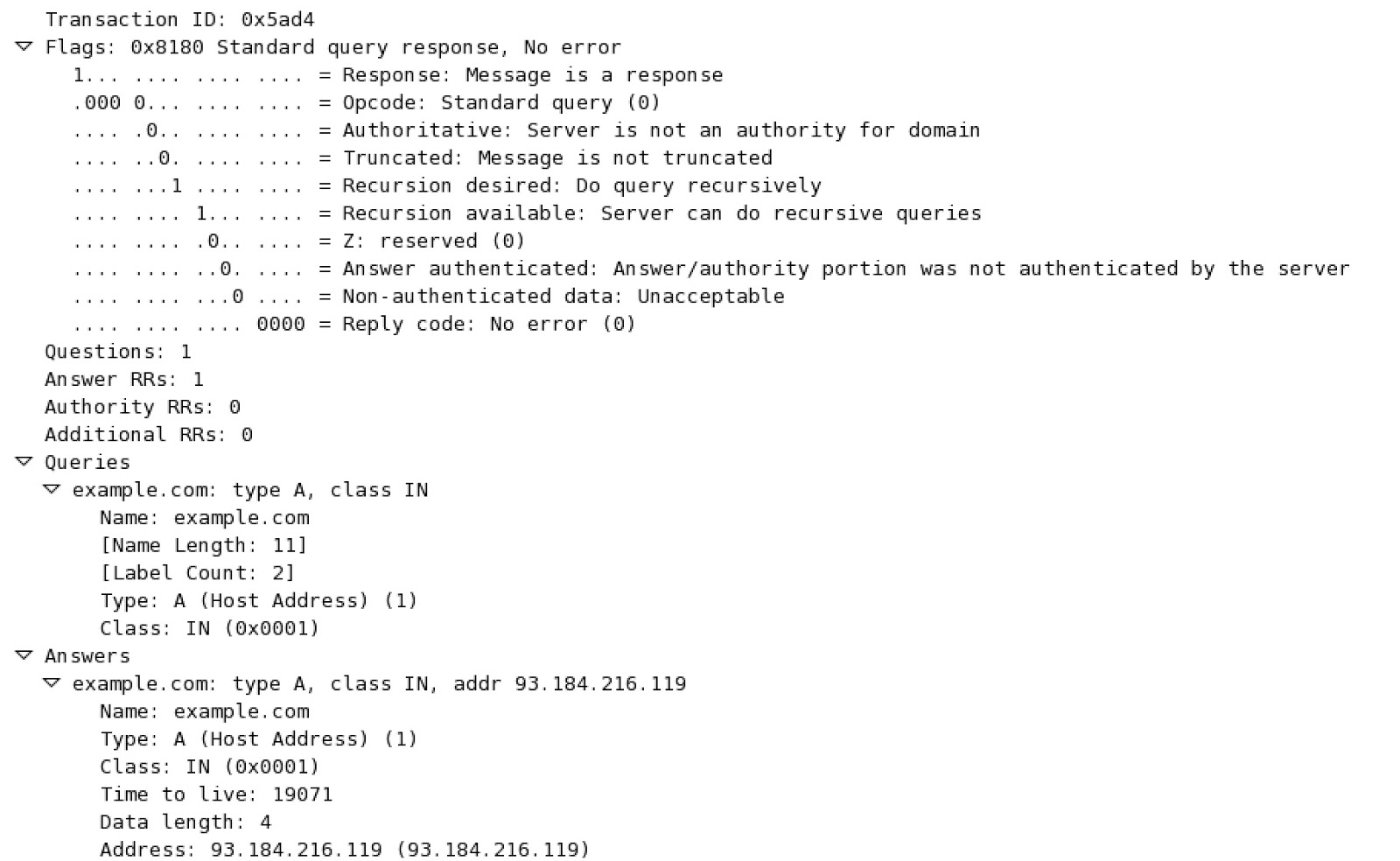
How DNS works
DNS is a distributed key/value database. The values returned can in theory be anything but in practice need to fit into well known types, such as addresses, mail exchanges, sever lists, free format text records etc. The keys consist of a name, type, and class. The name space is hierarchical (see below) and DNS information is “published” by Authoritative Servers. DNS Resolvers will locate the information requested by asking the appropriate authoritative servers by following the naming hierarchy from one Authoritative DNS server to the next one. The ISP typically provides a Recursive Resolver that will perform resolution on behalf of customers. You can also use a public resolver like the ones provided by Cloudflare (1.1.1.1, 1.0.0.1) , Google (8.8.8.8, 8.8.4.4) or OpenDNS (208.67.222.222, 208.67.220.220).
Web-enabled applications like browsers use something called a Stub Resolver to interact with the DNS. Once the application or browser has obtained the IP address of the website, they can access it using the HTTP or HTTPS protocols.
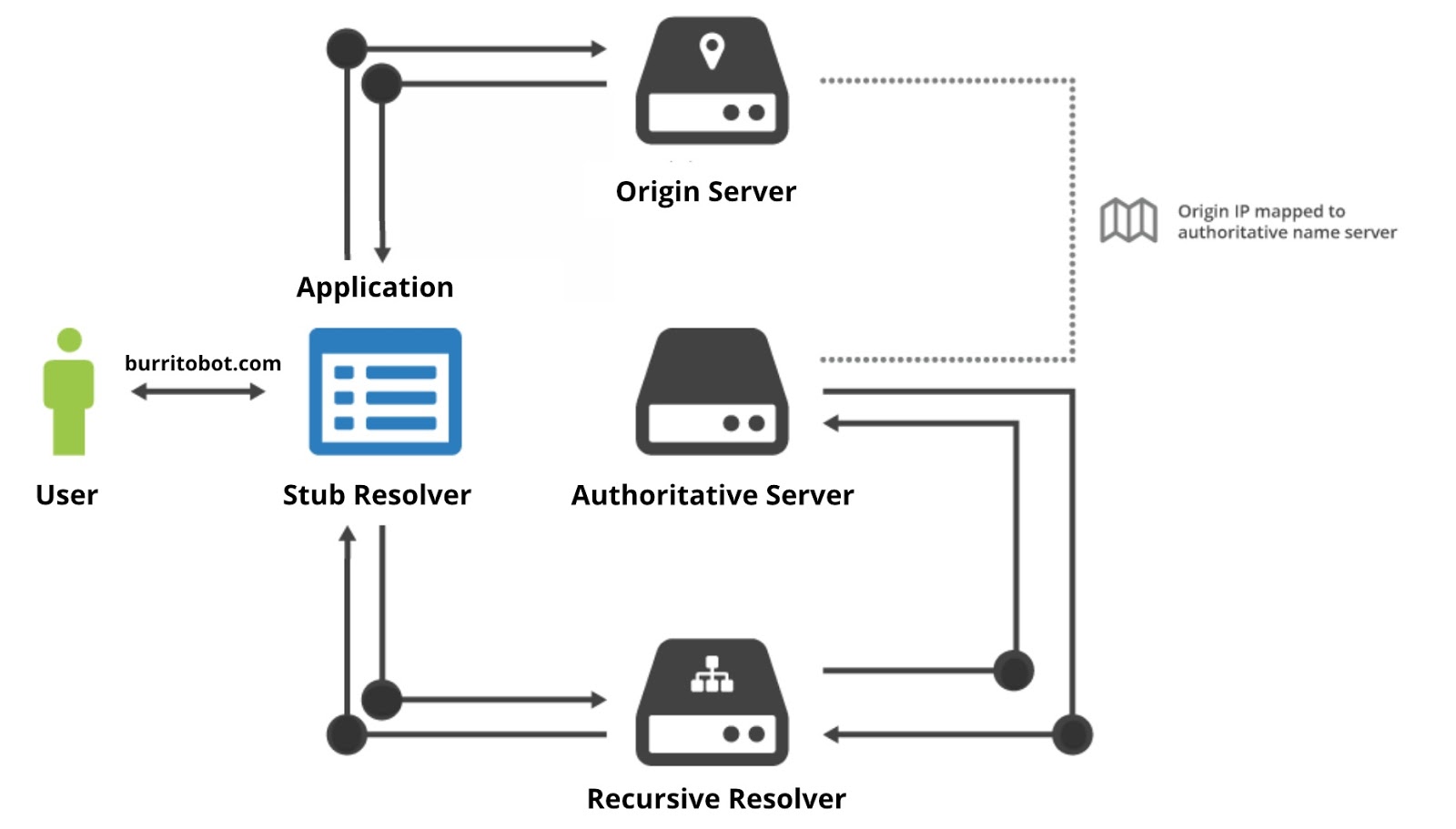
The DNS Namespace
The hierarchy of DNS namespace is well defined: DNS names consist of labels that are separated by dots. Thus www.example.com. consists of 4 labels www (leaf) example (domain) com (TLD) and . (i.e., the root). Resolvers search by starting at the longest match of the labels, i.e., if it only knows about the root then, it starts the search there. If resolvers know about .com, they start there.
There are 13 root servers maintained by 12 different organizations. The root zone is maintained by the Internet Assigned Numbers Authority (IANA), which is a part of ICANN, and is published by Verisign which operates two of the root servers. The contents of the root zone is a list of the authoritative servers for each TLD, but not much else. Thus, if a root DNS server receives a query for www.example.com it will answer with what is called a referral to .com resolvers. The answer from the root server contains a set of records called NS (Name Server). These records list the nameservers which should have more information about the requested zone, i.e., the .com servers.
Each one of the TLDs authoritative nameservers knows about the authoritative nameservers for the domains under them (example.com, cloudflare.com, google.com, etc.). Following this downward, you will eventually get to the server that can answer queries about records for the name you are looking for.
DNS is the largest distributed delegated database in the world. Delegated means that each name can have a different authority that can maintain the information, and any changes are reflected in the DNS. For this reason, it’s important that resolvers don’t keep what they learn forever. Similarly, it’s important that busy resolvers can reuse the information they have fetched. This reuse of information is accomplished by placing a TTL on every DNS record which tells resolvers how long they can reuse the records to answer questions. When a resolver returns a cached value, it adjusts the TTL downward reflecting how long the data has resided in its cache.
DNSSEC
In the early 1980s, when DNS was designed, there was no consideration for strong security mechanisms in the protocol. Computers at that time were underpowered compared with today’s machines, public key cryptography was a relatively new concept and highly regulated, and the network was much smaller, with fewer participants who were relatively well known and trusted. As the network grew and evolved, DNS remained unchanged as an insecure and unauthenticated protocol.
In 1993, the IETF started a public discussion around how DNS could be made more trustworthy. Eventually, a set of extensions to DNS, called Domain Name System Security Extensions (DNSSEC), were settled on, and formally published in 2005. These extensions replaced earlier proposals as a definitive way forward for securing DNS. Though it’s been almost a decade since this publication, DNSSEC is still far from mainstream adoption.
There are several catalysts pushing DNSSEC adoption, one of which is Dan Kaminsky’s cache poisoning attack from 2008. This attack highlighted the significant trust issues in traditional DNS, and how DNSSEC is well positioned to solve them. However, even after a significant amount of work, adoption is lagging — there are several factors holding DNSSEC adoption back. Among them are network operators that prefer stability to complexity (for good reason). Another difficulty with DNSSEC adoption is that there is no universal consensus around whether DNSSEC is the right tool to secure the DNS.
The security extensions to DNS add protection for DNS records, and allow the resolvers and applications to authenticate the data received. These powerful additions will mean that all answers from the DNS can be trusted. Earlier you learned how DNS resolution starts at the root nameserver, and works down (e.g., for www.example.com it starts at the root server, then “com”, then “example.com”). This is the same way that trust is conferred via DNSSEC. The DNS root is the definitive root of trust, and a chain of trust is built to the root from any DNS entry. This is a lot like the chain of trust used to validate TLS/SSL certificates, except that, rather than many trusted root certificates, there is one trusted root key managed by the DNS root maintainer IANA.
The point of DNSSEC is to provide a way for DNS records to be trusted by whoever receives them. The key innovation of DNSSEC is the use of public key cryptography to ensure that DNS records are authentic. DNSSEC not only allows a DNS server to prove the authenticity of the records it returns. It also allows the assertion of “non-existence of records”.
The DNSSEC trust chain is a sequence of records that identify either a public key or a signature of a set of resource records. The root of this chain of trust is the root key which is maintained and managed by the operators of the DNS root. DNSSEC is defined by the IETF in RFCs 4033, 4034, and 4035.
There are several important new record types:
- DNSKEY: a public key, used to sign a set of resource records (RRset).
- DS: delegation signer, a hash of a key.
- RRSIG: a signature of a RRset that share name/type/class.
A DNSKEY record is a cryptographic public key, DNSKEYs can be classified into two roles, which can be handled by separate keys or a single key
- KSK (key signing key): used to sign DNSKEY records.
- ZSK (zone signing key): used to sign all other records in the domain is authoritative for.
For a given domain name and question, there are a set of answers. For example, if you ask for the A record for cloudflare.com, you get a set of A records as the answer:
cloudflare.com. 285 IN A 198.41.212.157
cloudflare.com. 285 IN A 198.41.213.157
The set of all records of a given type for a domain is called an RRset. An RRSIG (Resource Record SIGnature) is essentially a digital signature for an RRset. Each RRSIG is associated with a DNSKEY. The RRset of DNSKEYs are signed with the key signing key (KSK). All others are signed with the zone signing key (ZSK). Trust is conferred from the DNSKEY to the record though the RRSIG: if you trust a DNSKEY, then you can trust the records that are correctly signed by that key.
However, the domain’s KSK is signed by itself, making it difficult to trust. The way around this is to walk the domain up to the next/parent zone. To verify that the DNSKEY for example.com is valid, you have to ask the .com authoritative server. This is where the DS record comes into play: it acts as a bridge of trust to the parent level of the DNS.
The DS record is a hash of a DNSKEY. The .com zone stores this record for each zone that has supplied DNSSEC keying information. The DS record is part of an RRset in the zone for .com and therefore has an associated RRSIG. This time, the RRset is signed by the .com ZSK. The .com DNSKEY RRset is signed by the .com KSK.
The ultimate root of trust is the KSK DNSKEY for the DNS root. This key is universally known and published.
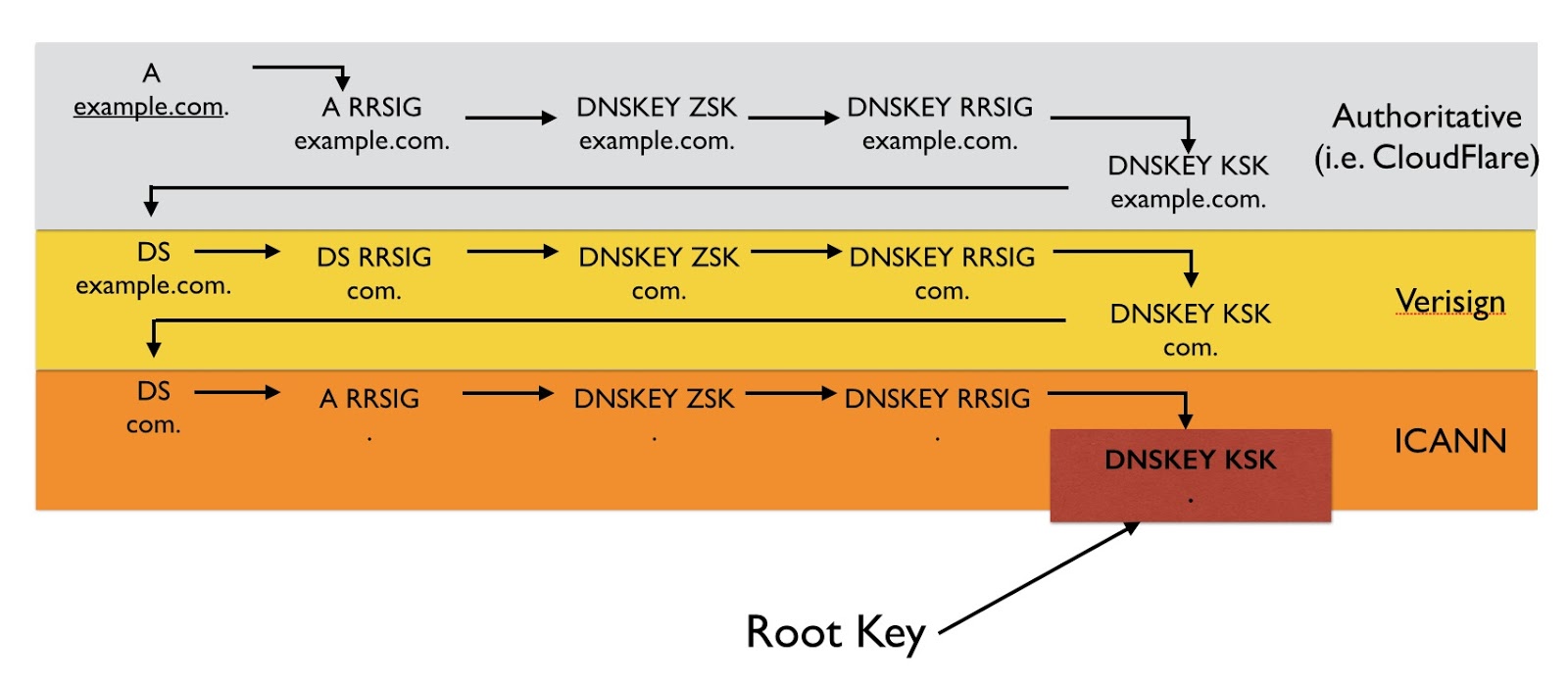
By following the chain of DNSKEY, DS and RRSIG records to the root, any record can be trusted.
These records are enough to prove the integrity of a resource record, but something more is needed in order to prove that a record does not exist. This is where two additional record types, NSEC and NSEC3, come into play.
If a DNS authoritative server knows there is no record for a specific request, it has a way to respond to such requests. When the name asked for does not exist, it returns a message that has return code (RCODE) NXDOMAIN. When the name exists, but the requested type does not, it returns a NODATA response, i.e., empty answer.
These non-existence answers are unauthenticated and could be forged by a third party just like any other DNS response. However, DNSSEC solves this problem by creating a record type that expresses what names exist, and what types reside at each name. This record is called NSEC. An NSEC can be signed by DNSSEC, and validated up to the root. Typically, NSEC is used to cover gaps between all the domains with records in the zone. In most cases, this effectively doubles the number of records in the zone, but allows an authoritative nameserver to reply with a signed response for any question.
The zone ietf.org. uses NSEC records. Asking for ‘trustee.ietf.org’ would give you a positive answer with an IP address and an RRSIG record. Asking for ‘tustee.ietf.org’ would give you a negative answer ‘there are no name between trustee.ietf.org and www.ietf.org’, with a corresponding RRSIG. For example:
Question:
tustee.ietf.org/A
Answer:
trustee.ietf.org. 1683 IN NSEC www.ietf.org. A MX AAAA RRSIG NSEC
This means that there are no names the zone in between trustee.ietf.org and www.ietf.org, when sorted alphabetically, effectively proving that tustee.ietf.org does not exist.
RFC5155 defines a obufscated way to deny existence via the NSEC3 record. NSEC3 uses similar logic, but for the names are hashed. Asking for examplf.com (e comes before f) would give you ‘there are no records with hashes between A and B’, where A is the next closest hash lexicographically before the hash of examplf.com, and B is the next closest after.
Kaminsky’s Attack
In 2008, Dan Kaminsky revealed an attack on the DNS system which can trick a DNS recursive resolvers into storing incorrect DNS records. Once the nameserver has stored the incorrect response, it will happily return it to everyone who asks until the cache entry expires (usually dictated by the TTL). This is so-called “DNS poisoning” attack could allow arbitrary attacker to trick DNS, and redirect web browsers (and other applications) to incorrect servers allowing them to hijack traffic.
DNS poisoning attacks are simple to describe, but difficult to pull off. Take the sequence of events:
- Client queries recursive resolver
- Recursive resolver queries authoritative server
- Authoritative server replies to recursive resolver
- Recursive resolver replies with an answer to the client
Kaminsky’s attack relies on the fact that UDP is a stateless protocol and that source IP addresses are blindly trusted. Each of the requests and responses described here is a single UDP request containing to and from IP addresses. Any host can in theory forge the source address on UDP message making look like it came from the expected source. Any attacker sitting on a network that does not filter outbound packets can construct a UDP message that says it’s from the authoritative server and send to the recursive resolver.
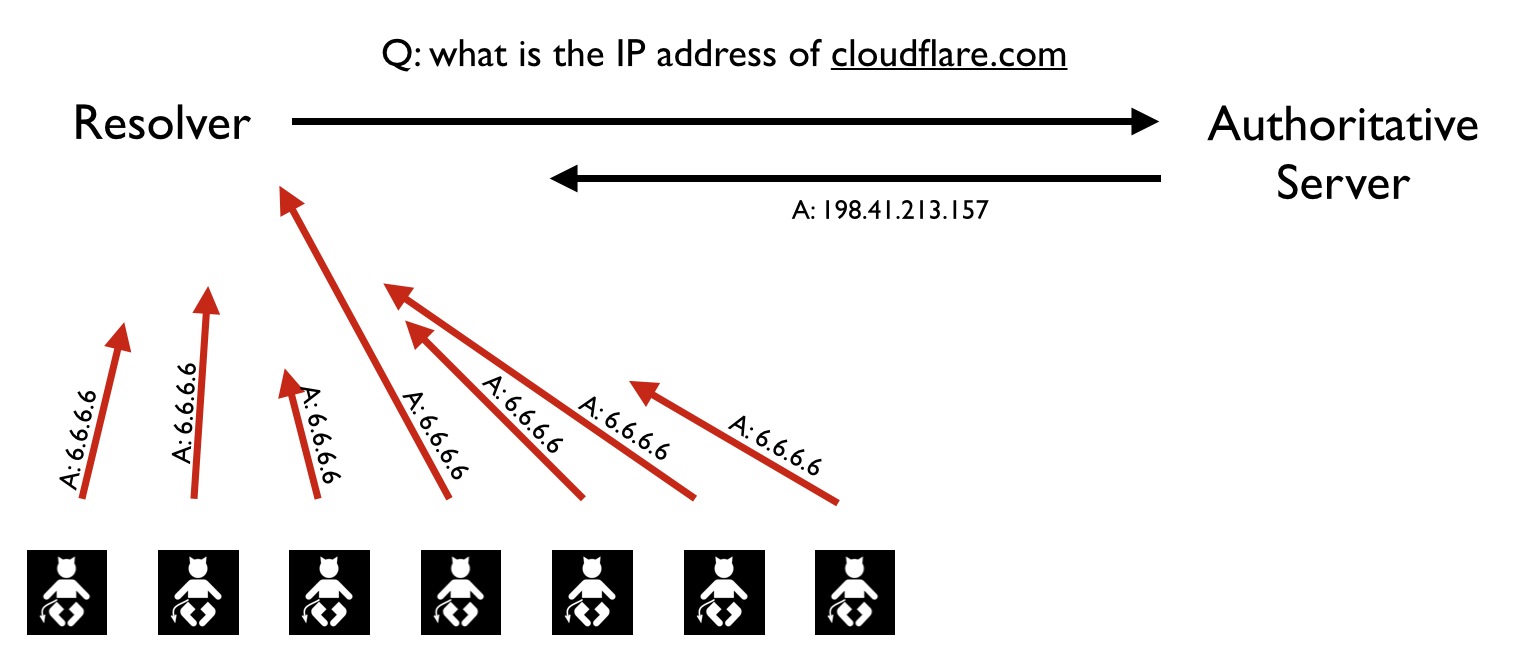
Of the requests above, message number 3 is a good target to attack. This is because the recursive resolver will accept the first answer to its question that matches its query. So, if you can answer it faster than the authoritative server, the recursive resolver will accept your answer as the truth. This is the core of the attack:
- Pick a domain whose DNS entries you want to hijack.
- Send a request to the recursive resolver for the record you want to poison.
- Send many fake UDP responses pretending to be the authoritative server with the answer of your choosing (i.e. point the A record to an IP you control).
If one of your malicious—acceptable—responses arrives ahead of the real response, the recursive resolver will believe your record and cache it for as long as the TTL is set. Then any other clients asking for the poisoned record will be directed to your malicious servers.
There are some complications that make this harder than it sounds in practice. For example, you have to guess:
- The request ID—a 16-bit number
- The authoritative server address that the query was sent to
- The recursive resolver address used to send the query
- The UDP port used to send the query to the authoritative server
When Kaminsky’s attack was originally proposed, many of these values were easily guessable or discoverable, thus making DNS poisoning a real threat. Since then, request ID, port randomization, and source address rotation have made this specific attack more difficult to pull off—but not impossible.
The fundamental issue that allows this kind of attack to happen is that there is no way for the resolver to validate that the records are what they are supposed to be. Note: if the attacker is in position to see the query traffic from the recursive resolver, it has all the information it needs to forge answers (see http://www.wired.com/2014/03/quantum/).